퍼포먼스 마케팅을 위한 "최적화 알고리즘"의 이해-1
퍼포먼스 마케팅을 위한 "최적화 알고리즘"의 이해-1
① 마케터를 위한 머신러닝 기반의 최적화 알고리즘 살펴보기
퍼포먼스 마케팅에서 익숙하게 접하면서도 정확히 어떤 의미인지 파악이 어려운 단어가 머신러닝이다. 데이터를 통해 시스템을 학습시키면 정확도가 올라가서 더 많은 구매, 인스톨, 회원가입 등을 일으킬 수 있다고 알려져 있지만 마케터 입장에서 어떤 일들이 일어나는지 깊이 알기엔 난감한 점이 많다. 머신러닝은 수학과 코딩의 산물이고, 수식에 대한 이해와 직접 코딩해보는 경험이 없이 스토리텔링만으로 이해하기에는 장님 코끼리 만지는 것과 비슷한 것 같다. 그럼에도 퍼포먼스 마케터는 머신이 학습한다는 것은 정확히 무엇을 의미하는 것인지, 그리고 광고 매체가 학습 중이라는 것, 그리고 학습이 완료 되었다는 것은 무엇을 의미하는 것인지 최대한 밝게 알아둘 필요가 있다. 결국 이것이 RTB 시스템과 함께 모든 광고 매체를 아우르는 핵심이기 때문이다.
머신러닝이란 무엇인가?
머신러닝은 데이터로부터 학습하도록 컴퓨터를 프로그래밍 하는 것이다. 1959년에 머신러닝이라는 용어를 대중화 시킨 인공지능 분야의 선구자인 아서 새뮤얼은 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야라고 하였다. 조금 더 실질적인 의미에서 머신러닝은 주어진 데이터로부터 패턴을 학습하여 예측 모델을 찾고, 찾아낸 모델을 통해 새로운 데이터에 대한 예측을 수행하는 것이다.

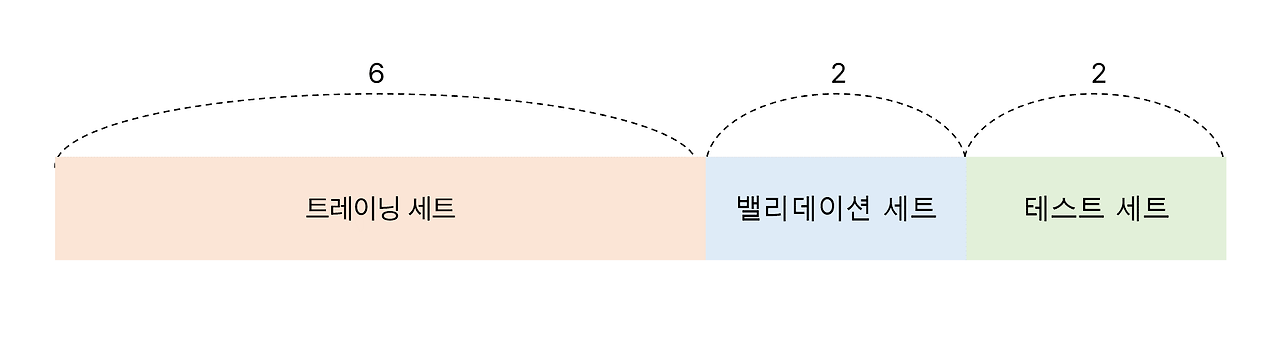
머신러닝에서 데이터는 시스템이 패턴을 학습하기 위해 사용하는 데이터 셋을 트레이닝 세트(Training Set), 모델을 검증하는데 사용하기 위한 밸리데이션 세트(Validation Set), 실제로 예측이 잘 되고 있는지 평가하기 위한 테스트 세트(Test Set)로 구분할 수 있다. 모델을 학습시킬 때에는 가지고 있는 데이터 셋을 트레이닝 세트 6, 밸리데이션 세트 2, 테스트 세트 2의 비율로 크기를 나누어 학습을 진행한다.
머신러닝은 메일이 스팸인지 아닌지 분류하는 스팸 필터링 기법처럼 단순한 것 부터, 넷플릭스를 통해 유명해진 추천 알고리즘, 리멤버에서 활용하고 있는 명함 인식 OCR 기술, 틱톡, 스노우 등에서 활용되고 있는 카메라 필터까지 굉장히 다양한 영역에서 활용되고 있으며, 광고 매체에서 "전환을 일으킬 만한 유저"를 분류해내는 것도 이러한 머신러닝의 분류 기법의 일부이며, "전환을 일으킬 만한 유저를 분류해내는 모델"을 포함하여 "클릭을 할만한 유저를 분류해내는 모델, 랜딩 페이지 조회를 할만한 유저를 분류해내는 모델, 동영상을 3초이상 볼만한 유저를 분류해내는 모델" 등등을 학습시키는 것이 광고 매체의 머신러닝이다.
머신러닝을 사용하는 이유
아래 그림처럼 컴퓨터는 동영상, 이미지, 텍스트, 사람들이 웹 내에서 움직이는 행동 패턴 등을 포함한 모든 데이터를 숫자화 하여 읽어들인다. 기존의 프로그래밍 방식은 이렇게 읽어들인 데이터에 우리가 알고 있는 어떤 규칙들을 적용하여 이 데이터가 뜻하는 것은 무엇인지 판별하는 것이었다. 이러한 방식을 룰베이스 방식이라 한다.
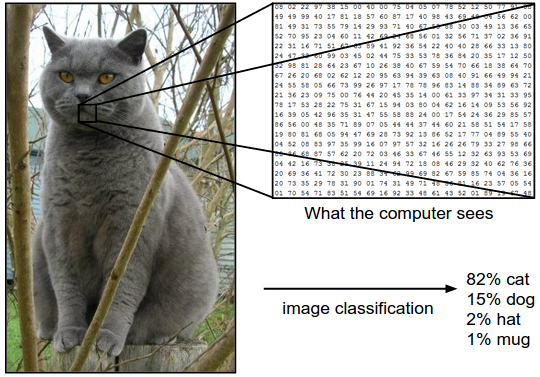
출처: 스탠포드 CS231n 강의 노트
이렇게 컴퓨터가 숫자화 하여 데이터를 읽어들인다고 할 때, 하단 그림처럼 고양이가 가지고 있는 특징들을 찾고, 그 특징들이 숫자로 변환되었을 때 갖는 패턴들을 규칙화 하여 미리 저장해두었다가 새로운 이미지 데이터가 들어오면 미리 설정해둔 규칙들을 기반으로 고양이인지 아닌지 판단하는 것이 룰베이스 방식의 분류 기법이다.
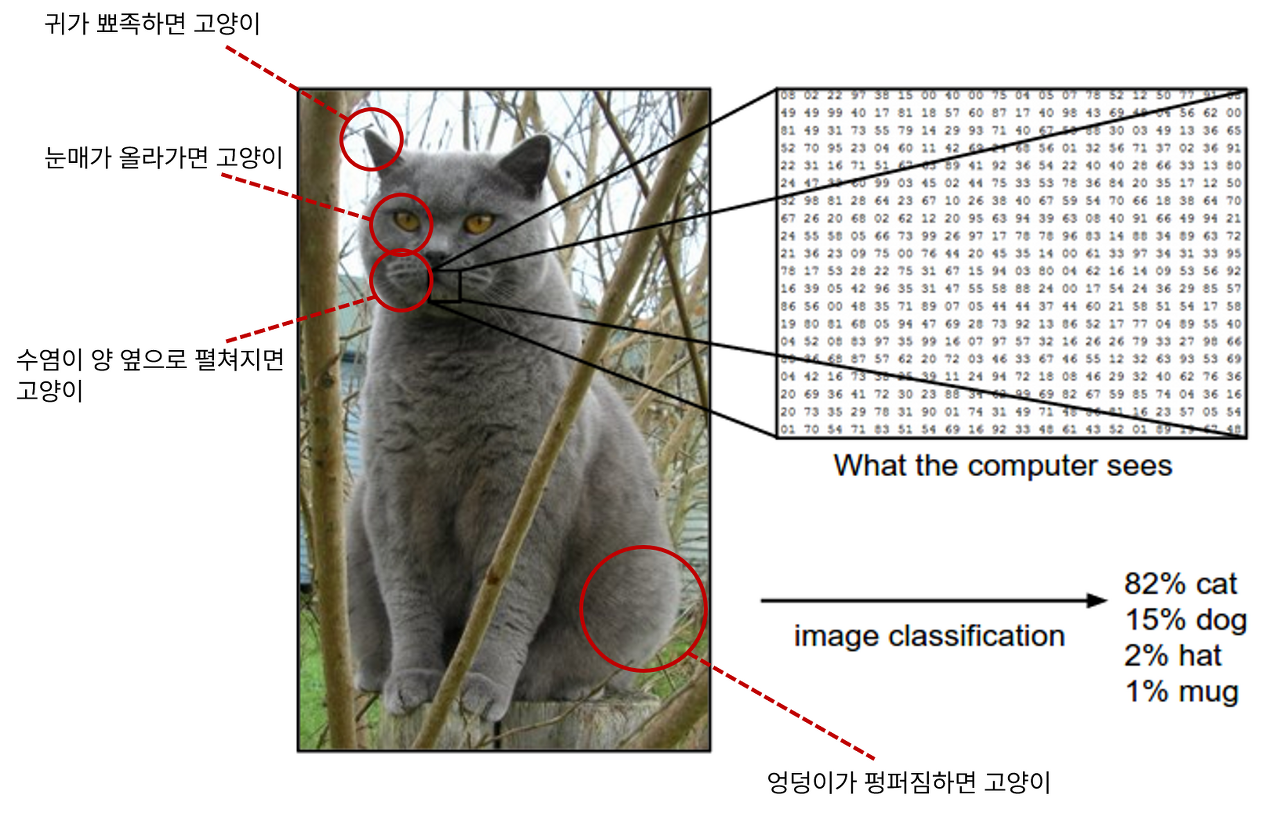
룰베이스 방식의 단점은 규칙들을 충족하는 다른 대상을 구분해내기 어렵다는 것이다. 아래의 그림 처럼 어떤 규칙을 미리 정해놓고 머핀인지 강아지인지, 고양이인지 빵이나 아이스크림인지 구분하기 어려운 상황들이 발생하고, 이 때 마다 규칙을 추가하는 것 만으로는 모델의 성능을 개선하기 어려울 뿐더러 규칙이 점점 복잡해져서 유지 보수에도 어려움을 겪게 된다. (물론 아래의 예시는 머신러닝을 사용해도 구분해내기 어려운 데이터 셋 예시이다.) 반면 머신러닝을 활용하면 새로운 학습 데이터를 추가할 때마다 기존의 모델을 업데이트하여 성능을 개선할 수 있고 아래의 그림에 대해서도 더 많은 데이터 셋을 확보할 수 있다면 개와 고양이의 패턴에 대해서도 지속적으로 학습해 낼 수 있기 때문에 유용하다.

또한 머신러닝은 기존에 해법이 알려지지 않은 분야에서도 해법을 찾아낼 수 있는 강점이 있다. 퍼포먼스 마케팅 분야에서도 메타, 구글, 네이버, 카카오는 RTB 시스템을 기반으로 축적된 유저의 행동 데이터를 통해 특정 이벤트를 일으킬 가능성이 높은 유저들의 패턴을 지속적으로 학습해가고 있으며, 이 지점에서 퍼포먼스 마케팅은 검색결과 상위 노출과 점유율 관리 위주로 진행되던 전통적인 키워드 마케팅과 차이가 있다는 사실이 드러난다.
머신러닝의 기본 원리
머신러닝은 아래와 같이 어떤 데이터 세트가 주어졌을 때, 그 데이터 세트를 가장 잘 설명하면서도 새로운 데이터가 수집되었을 때 그 데이터에 대한 예측치를 가장 잘 도출해내는 모델을 찾아내는 것을 목표로 한다. 부동산 가격 예측 예시를 통해 머신러닝의 기본적인 요소들에 대해서 이해해보자.

위 그림을 살펴보면 32개의 부동산 면적 및 가격에 대한 데이터와 이 데이터를 2차원 평면에 뿌려놓은 산포도로 구성되어 있다. 오른쪽의 산포도는 면적과 부동산 가격의 관계를 설명하는 빨간색의 일차함수 그래프를 포함하고 있다. 이것을 수식으로 표현하면 아래와 같다.
부동산 가격(만원) = a * 면적(제곱미터) + b
그럼 이 선이 주어진 데이터를 가장 잘 설명하게 하기 위해서 어떻게 선의 위치를 조정하면 좋을까? 이 때 사용하는 것이 오차 제곱의 합을 최소화 하는 LSE(least squared error)이다. LSE가 무엇인지 어렵게 생각할 것 없이 아래의 그림을 살펴보자.

위 그림에서 오차는 각 파란 점들과 일차함수 그래프인 빨간선 사이의 거리를 나타낸 파란 화살표들의 길이를 말한다. 각 오차의 제곱을 모두 더한 값을 최소화 하는 방향으로 빨간선의 위치를 조정해나가다 보면, 결국 오차 제곱의 합이 최소화 되는 빨간선을 그릴 수 있을 것이다. 그렇다면 오차제곱의 합은 어떻게 구하는 것일까?
Gradient Descent(경사 하강법)
머신러닝은 경사하강법을 통해 오차제곱의 합을 최소화하고 예측 모델의 성능을 극대화 하며 이 과정을 모델의 "학습"이라 한다. 경사하강법은 안개가 낀 깜깜한 밤에 산에서 하산하는 방법과 유사하다고 말한다. 앞이 보이지 않을 때 산에서 내려가려면 지금 내가 서있는 자리보다 경사가 아래로 기울어진 지면을 향해 한발씩 내딛으면 반드시 가장 낮은 지점으로 도달하는 것과 같다.
경사 하강법(傾斜下降法, Gradient descent)은 1차 근사값 발견용 최적화 알고리즘이다. 기본 개념은 함수의 기울기(경사)를 구하고 경사의 반대 방향으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다. -위키피디아, 경사하강법
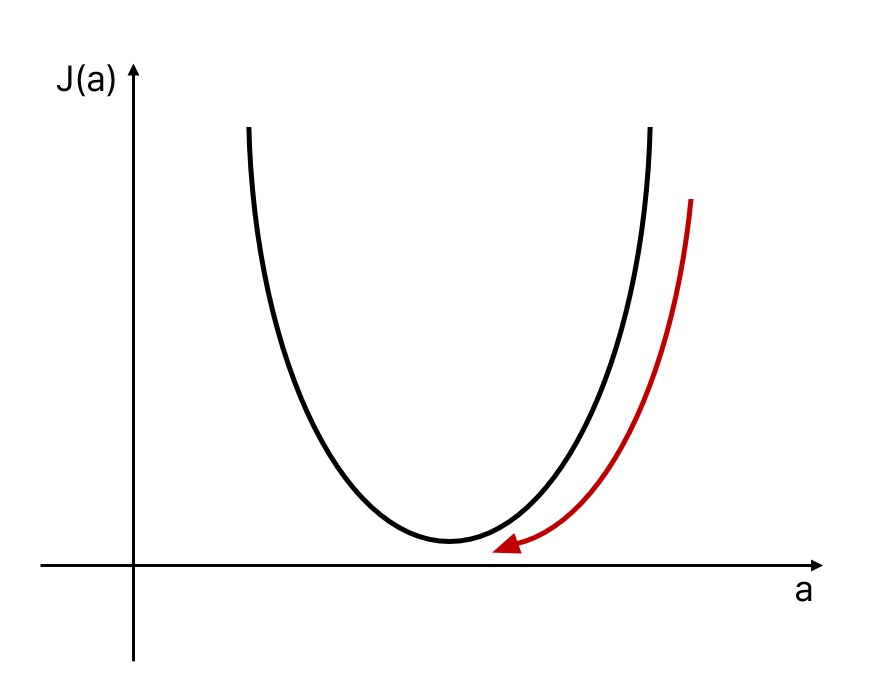
이것을 아래로 내려가는 것이 아니라 산 정상을 향해 올라가는 것으로 바꾸어 생각해보면 훨씬 직관적이다. 아래 그림을 예로 들어보면, 기울기가 가파라지는 방향으로 계속 움직이다 보면 어느 순간 정상에 도달해 있게 된다. 정상인지 아닌지 판단하는 방법 또한 간단하다. 어떤 방향으로든 한발 내딛었을 때 현재보다 아래로 내려간다면 그 지점이 정상일 것이다.
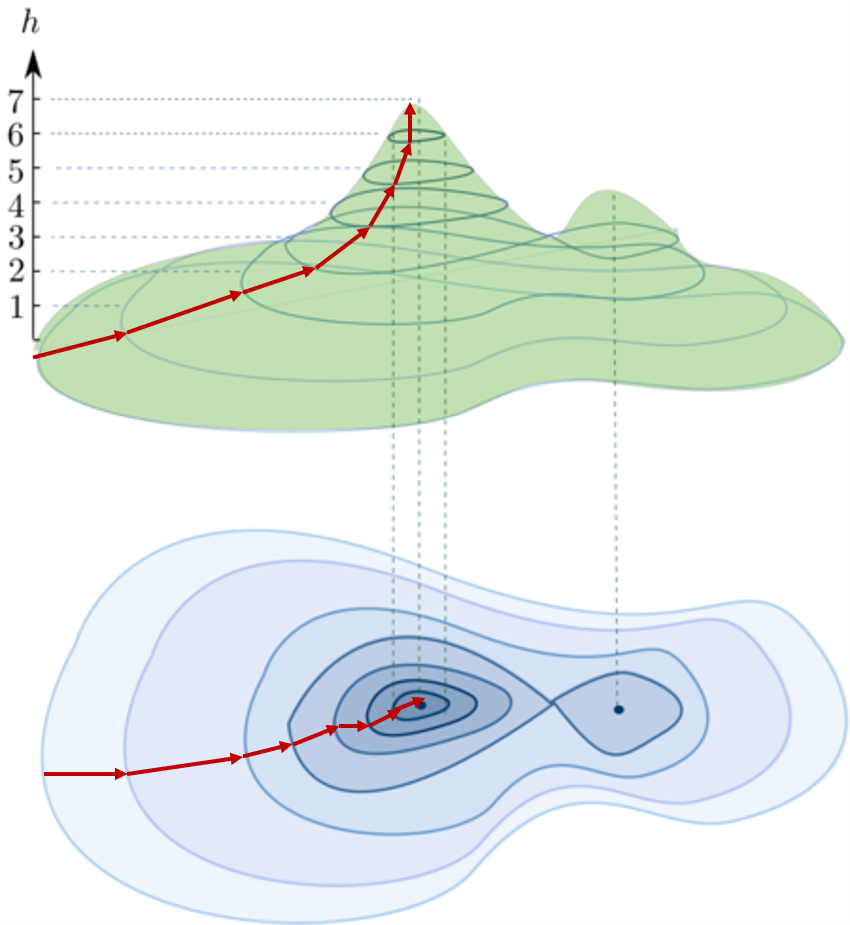
출처: https://terms.naver.com/entry.naver?docId=4125487&cid=60207&categoryId=60207
(여기서 부터는 약간의 수식과 그래프가 등장하므로 필요없다고 느끼는 분들은 스킵하세요.)
경사하강법은 이렇게 정상으로 향하는 과정을 반대로 뒤집어서 생각하는 것이다. 오차 제곱의 합에 대해 경사하강법을 쓰기 위해 아래와 같이 J(a, b)라는 cost function을 가정하는데, 이 cost function은 아래로 볼록한 성질을 갖는 2차 함수가 된다. 이 cost function의 최저점이 예측 모델의 성능을 극대화하는 지점이 되며, 최저점에 있을 수 있게 하는 a, b를 찾는다면 우리는 y = ax + b라는 예측 모델을 찾을 수 있게 되는 것이다.
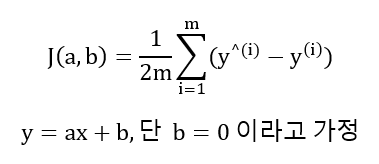
여기서 cost function의 최저점을 찾기 위하여 J를 a와 b에 대해 미분하면 되는데, 위 수식에서 b=0으로 가정했으므로 a에 대해서만 미분하면 된다. 미분을 통해 나온 에러값을 일정 크기 만큼 a와 b에 반영하는 것을 계속 반복하면 y = ax + b를 찾아낼 수 있다. 이 과정의 핵심은 경사하강법을 통해 예측 모델의 성능을 극대화 하는 찾는다는 것이며, 이 때 아래 그림처럼 cost function J가 최소값이 되는 방향으로 머신러닝 학습이 진행된다.
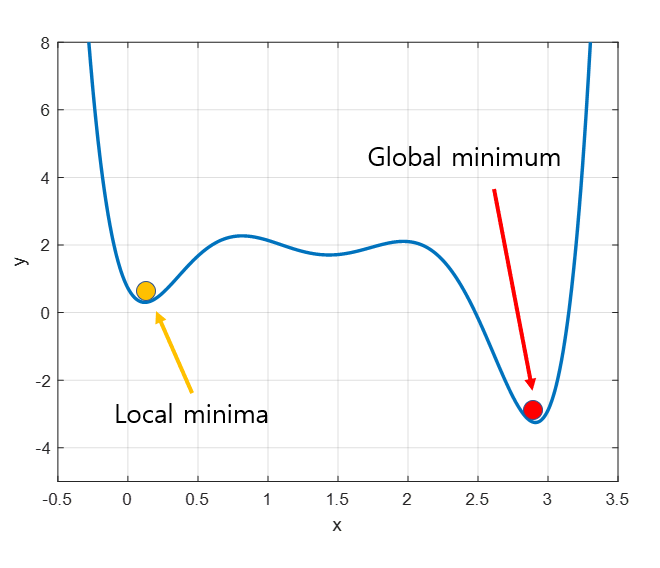
Global minimum vs Local minima
다시 산 그림으로 돌아가보자. 산 그림을 보면 사실 최정상 봉우리와 두번째로 높은 봉우리가 함께 있다. 때문에 만약 운이 나빠서 두번째로 높은 봉우리 쪽에서 등산을 시작하여 경사가 가파른 방향으로 움직인다면 최정상에는 절대 다다를 수가 없다. 두번째로 높은 봉우리도 최정상과 마찬가지로 어느 방향으로 발을 내딛는다고 하여도 아래로 내려가게 되기 때문이다. 이 경우 머신러닝 학습은 종료되게 된다.
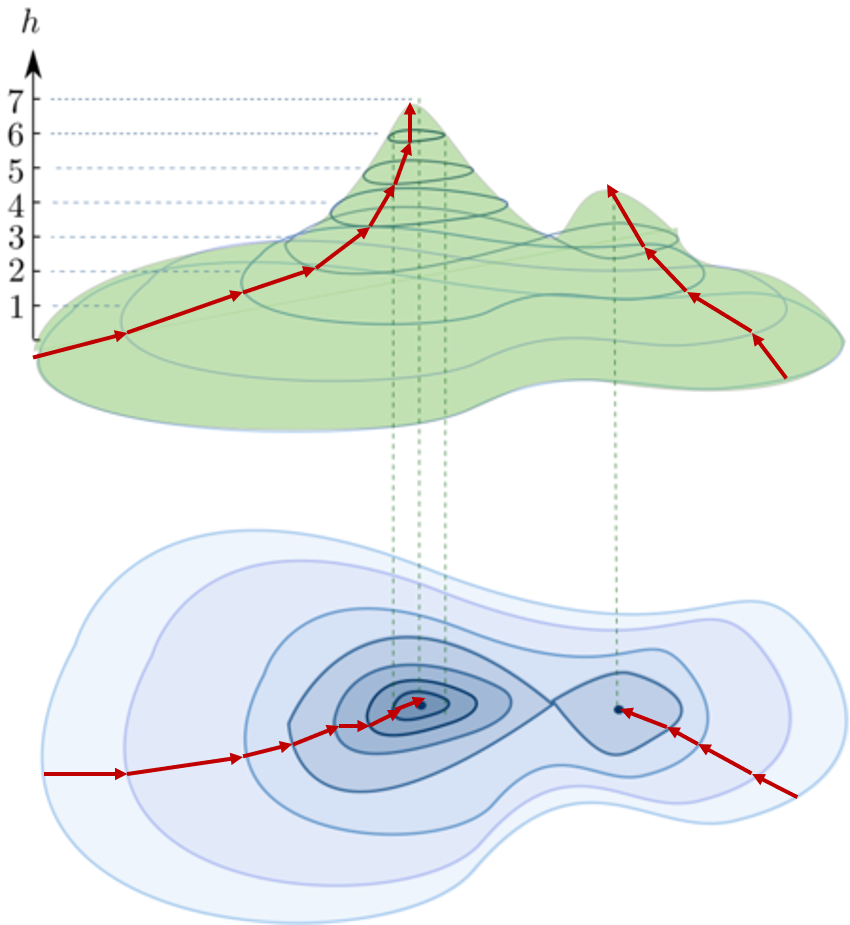
이 경우 우리는 캄캄한 밤에 안개 마저 자욱한 상황이라고 하였으므로 옆에 최정상 봉우리가 있는지 알 수 없고, 내가 있는 이곳이 가장 정상이라고 생각하게 된다. 머신러닝은 완료된 것이나 예측 모델의 성능이 떨어지게 되는 것이다. 만족스럽지 않은 예측 결과만 주어진 상황에서, 더 높은 정상이 있는지 모르는 상태에서 학습을 다시 시작해야 할지도 판단하기 어렵고 어떤 출발점에서 시작해야 있는지 없는지 알 수 없는 최정상에 다가설 수 있는지도 판단하기 어렵게 된다. 여기서 진짜 최정상 봉우리를 Global minimum, 가짜 최정상 봉우리를 Local minima라 부른다.
출처: https://angeloyeo.github.io/2020/08/16/gradient_descent.html
봉우리 문제를 다시 cost function에 대한 경사하강법 과정으로 가져오면 위 그래프처럼 표현할 수 있다. 노란색 점이 Local minima에 빠지게 되면 시간을 더 들여도 학습이 나아질 수 없다. 최근에는 머신러닝 과정에서 Local minima 문제가 발생하는 경우가 적지만, 퍼포먼스 마케터로서 명심해야 할 점은 머신러닝이 완료되었다고 하더라도 그것이 베스트가 아닐 수 있다는 전제를 항상 깔아두어야 한다는 것이다.
머신러닝의 작동방식이 퍼포먼스 마케터에게 주는 함의
부동산의 사례에서 면적 외에 고려할 수 있는 변수들은 준공년도, 지하철역과의 거리, 기타 등등 추가될 수 있는 변수들이 있다. 하지만 3개 이상의 변수는 사람의 눈으로 이해할 수 있는 시각화를 할 수가 없다. 만약 부동산에 대한 빅데이터가 완벽하게 구축되어 부동산 가격에 영향을 주는 1만개의 요소가 발견되었고 이것을 모두 고려하면 완벽하게 부동산 가격을 예측할 수 있는 상황이라고 한다면, 우리는 시각화 할 수는 없지만 수식으로 표현하여 솔루션을 찾을 수 있다. 광고 시스템 또한 학습시키려고 하는 최적화 모델은 광고 소재, 광고 세트, 캠페인, 유저 행동 데이터, 다른 광고와의 상호관계를 포함한 수십, 수백, 수천, 수만, 혹은 수억개의 변수로 구성이 되어 있을 것으로 추정된다. 이것을 아래와 같이 (말도 안되지만) 식으로 표현해볼 수 있다.
y = 소재_특성 * x1 + 이벤트_설정값 * x2 + 캠페인_설정값 *x3 + 타겟_행동데이터 * x4....
실제로 광고 매체에서는 위와 같이 말도 안되는 방식이 아니라, 이전 아티클에서 살펴보았던 RTB 시스템을 운영하며 수집해온 DSP, SSP, DMP 및 광고 반응 데이터들을 기반으로 수식을 구성해 두었을 것이다. 이것을 추정해보면 아래와 같은 형태일 것이라고 추정해볼 수 있다.
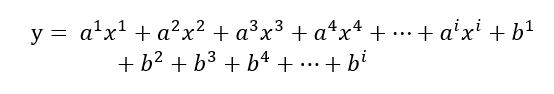
이렇게 수식이 구성되어 있다고 가정하는 것이 퍼포먼스 마케터에게 어떤 의미가 있을까? 바로 수식 안에 포함시킨 변수들에 포함되는 요소들에 대해 우리가 변화를 준다면 머신러닝 예측 모델에 영향을 줄 수 있다는 뜻이 된다. 그리고 그 변화들은 머신러닝 예측 모델이 진짜 최정상으로 더 빠르게 올라갈 수 있는 가이드가 될 수도 있고, 가짜 최정상에서 헤매도록 하는 함정이 될 수도 있다. 이를 염두에 둔다면 광고를 세팅해놓고 기다리는 것이 머신러닝 최적화의 전부라고 생각하는 것이 아니라, 매순간 마다 학습이 잘 될 수 있는 방향으로 생각해볼 수 있는 계기가 될 것이라고 생각한다.
※머신러닝에 대해 정확하게 더 공부해보고 싶다면 아래 추천드리는 두 강의를 순서대로 들어보세요. 마케터로서는 차고 넘치는 수준으로 개념에 대해 이해하는데 도움이 되실 것입니다.
1. 모두의 딥러닝(김성훈)
